inception
2017.01.23 19:02
https://norman3.github.io/papers/docs/google_inception.html
Google Inception Model.
https://arxiv.org/abs/1409.4842
- Tensorflow 공개 후 우리가 가장 많이 사용하는 Conv-Net 모델.
- 그냥 가져다 쓰기 보다는 원리를 좀 알고 쓰자는 생각에 간단하게 정리를 하는 페이지를 만든다.
- 일단 기본 Inception 모델을 설명하지만 추가로 Inception-v4까지 모두 설명한다.
- 다음의 논문들을 요약 정리한 것이다.
Inception. v1. (a.k.a GoogLeNet)
- 2014년 IRSVRC 에 VGG를 간신히 꺽고(?) 1등을 차지한 모델. (GoogLeNet)
- 이후 Inception 이란 이름으로 논문을 발표함. (Inception의 여러 버전 중 하나가 GoogLeNet 이라 밝힘)
- 관련 논문 : Going deeper with convolutions
- 2012년 Alexnet 보다 12x 적은 파라미터 수. (GoogLeNet 은 약 6.8M 6.8M 의 파라미터 수)
- 구글측 주장
- 알다시피 딥러닝은 망이 깊을수록(deep) 레이어가 넓을수록(wide) 성능이 좋다.
- 역시나 알다시피 현실적으로는 overfeating, vanishing 등의 문제로 실제 학습이 어렵다.
- 구현을 위한 현실적인 문제들.
- 신경망은 Sparsity 해야지만 좋은 성능을 낸다. (Dropout 생각해봐라)
- 논문에서는 데이터의 확률 분포를 아주 큰 신경망으로 표현할 수 있다면(신경망은 사후 분포로 취급 가능하므로),
- 실제 높은 상관성을 가지는 출력들과 이 때 활성화되는 망내 노드들의 클러스터들의 관계를 분석하여,
- 최적 효율의 토폴로지를 구성할 수 있다고 한다.
- 근거는 Arora 논문 을 참고한 내용이라 함.
- 하지만 이와는 반대로 실제 컴퓨터 연산에 있어서는 연산 Matrix가 Dense 해야 쓸데없는 리소스 손실이 적다.
- 정확히는 사용되는 데이터가 uniform distribution을 가져야 리소스 손실이 적어진다.
- 그럼 가장 좋은 방법은?
- Arora 의 논문 에서 희망을 보았다.
- 전체적으로는 망내 연결을 줄이면서(sparsity),
- 세부적인 행렬 연산에서는 최대한 dense한 연산을 하도록 처리.
- GoogLeNet 은 사실 Arora 논문 내용을 확인해보다가 구성된 모델임.
- 잡설이 길었다.
- Inception v1. 의 핵심은 Conv 레이어에 있음.
- Conv 레이어를 앞서 설명한대로 sparse 하게 연결하면서 행렬 연산 자체는 dense 하게 처리하는 모델로 구성함.
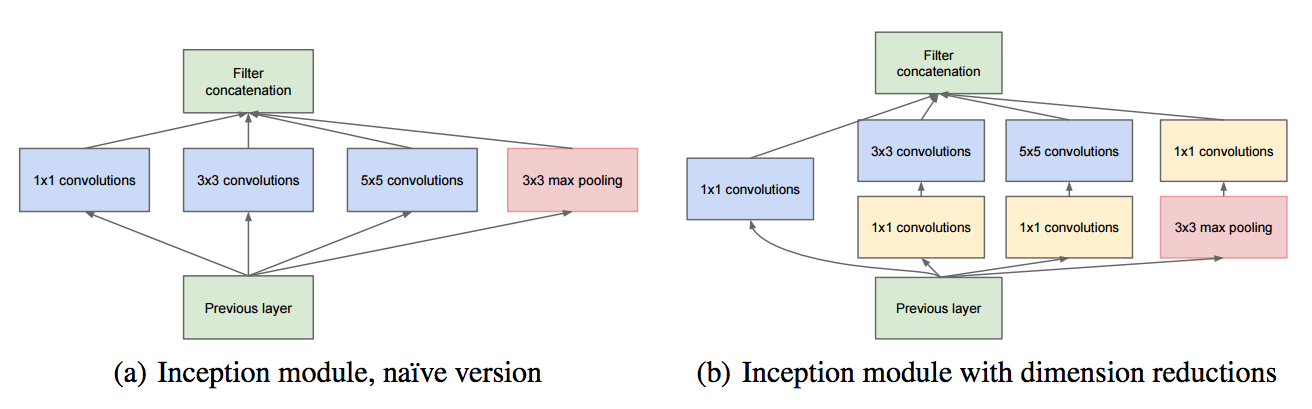
- Inception v1. 은 그냥 이 그림이 핵심임.
- 일단 (a) 모델을 보자. (CONV 연산이다.)
- 보통 다른 모델은 7x7 등 하나의 Convolution 필터로 진행을 하는데 여기서는 이런 식으로 작은 Conv 레이어 여러 개를 한 층에서 구성하는 형태를 취한다.
- 1x1 Conv?
- 이제는 흔한 Conv라 다들 알 수도 있는 내용이지만 그래도 간단히 정리해둔다.
- Conv 연산은 보통 3차원 데이터를 사용하는데 여기에 batch_size를 추가하여 4차원 데이터로 표기한다. (ex) : [B,W,H,C] [B,W,H,C]
- 보통 Conv 연산을 통해 W W , H H 의 크기는 줄이고 C C 는 늘리는 형태를 취하게 되는데,
- W W , H H 는 Max-Pooling 을 통해 줄인다.
- C C 는 Conv Filter 에서 지정할 수 있다. 보통의 Conv는 C C 를 늘리는 방향으로 진행된다.
- 이 때 1x1 연산은 Conv 연산에 사용하는 필터를 1x1 로 하고 C C 는 늘리는 것이 아니라 크기를 줄이는 역할을 수행하도록 한다.
- 이렇게 하면 C C 단위로 fully-conntected 연산을 하여 차원을 줄이는 효과(압축)를 얻을 수 있다. 이게 NIN. (Network in Network)
- (b) 는 개선 모델
- 사실 5x5 연산도 부담이다. (참고로 Inception v2. 에서는 이걸 3x3 연산 2회로 처리. 이건 뒤에 나온다)
- 그래서 이 앞에 1x1 Conv 를 붙여 C C 를 좀 줄여놓고 연산을 처리한다. (그래도 성능이 괜찮다고 함)
- 이로 인해 계산량이 많이 줄어든다.
- Max-Pooling 의 경우 1x1 이 뒤에 있는 이유
- 출력 C C 의 크기를 맞추기 위해 사용.
- Max-Pooling 은 C C 크기 조절이 불가능하다.
- 결론
- Conv 연산을 좀 더 작은 형태의 Conv 연산 조합으로 쪼갤 수 있다.
- 이렇게 하면 정확도는 올리고, 컴퓨팅 작업량은 줄일 수 있다.
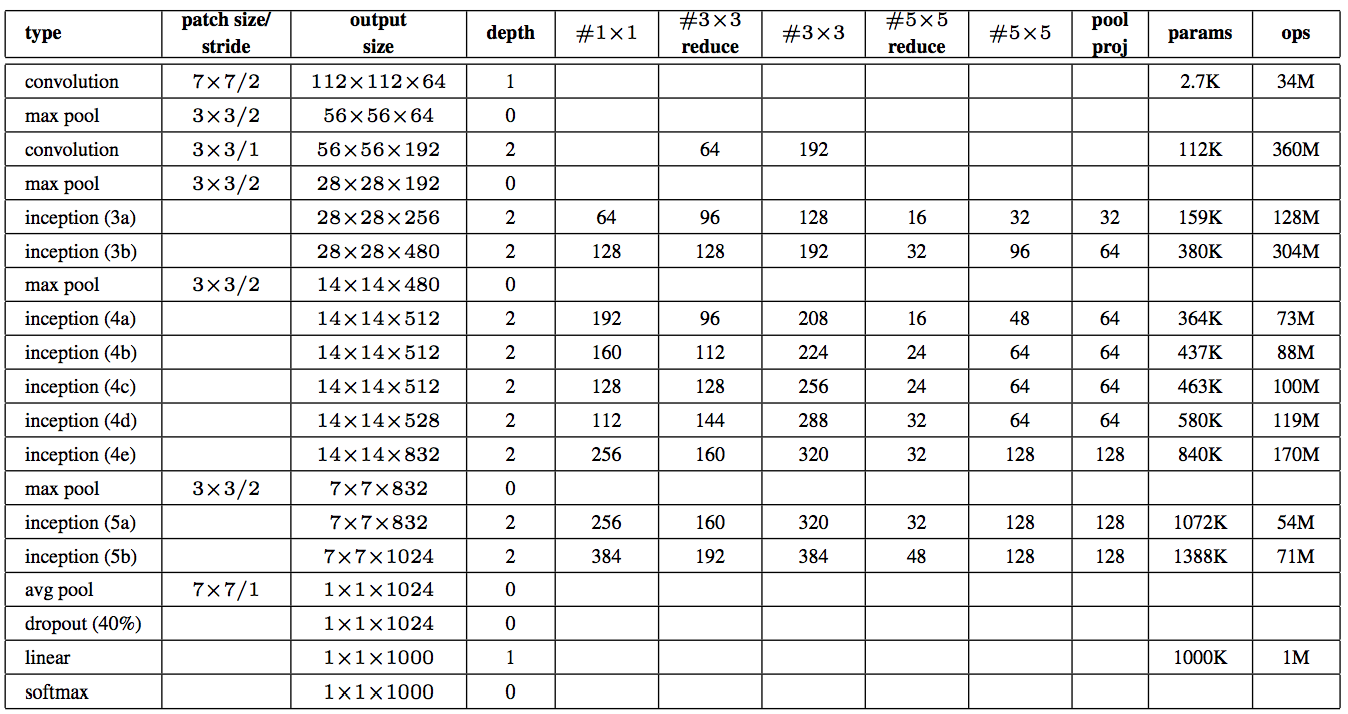
- 위의 표는 Inception 전체 Layer에서 사용되는 Conv 의 크기를 순서대로 나열한 표이다.
- 한번 정도는 진지하게 표를 살펴볼 필요가 있다.
- 위의 값은 GoogLeNet 을 구성한 값임.
- 입력 이미지 크기는 224x224x3 임.
- 레이어 초반에는 인셉션 모듈이 들어가지 않는다.
- 얘네들은 이걸 Stem 영역이라고 부르던데.. 어쨌거나 일반적인 Conv-Net 에서 보이는 가장 단순한 Conv-Pool 스타일을 따른다.
- 실험을 해보니 레이어 초반에는 인셉션이 효과가 별로 없어서 이렇게 한다고 한다.
- '’reduce’’ 라고 되어 있는 값은 앞단 1x1 Conv 의 C C (channel) 값을 의미한다.
- 그림으로 도식화하면 다음과 같다.
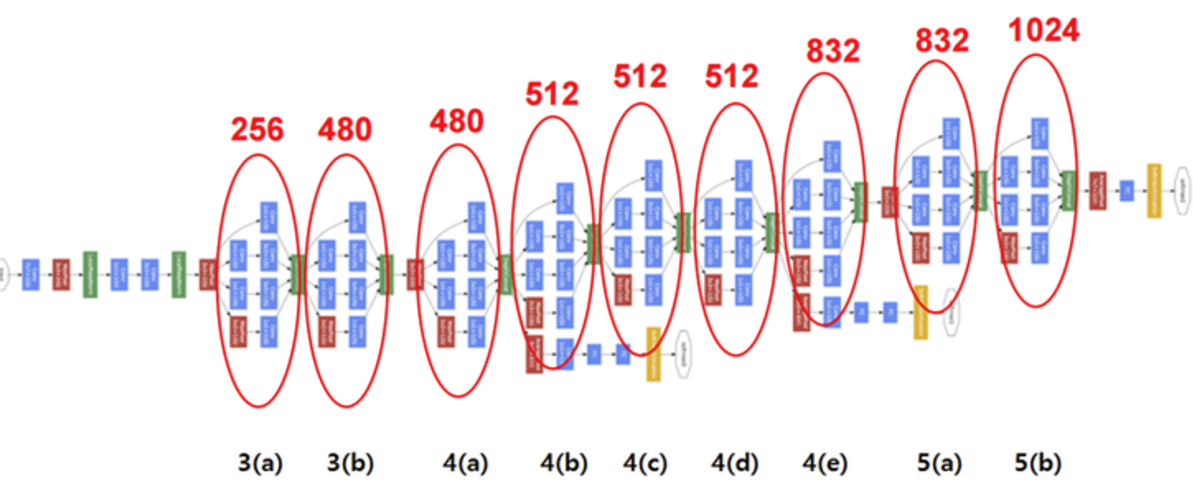
참고사항
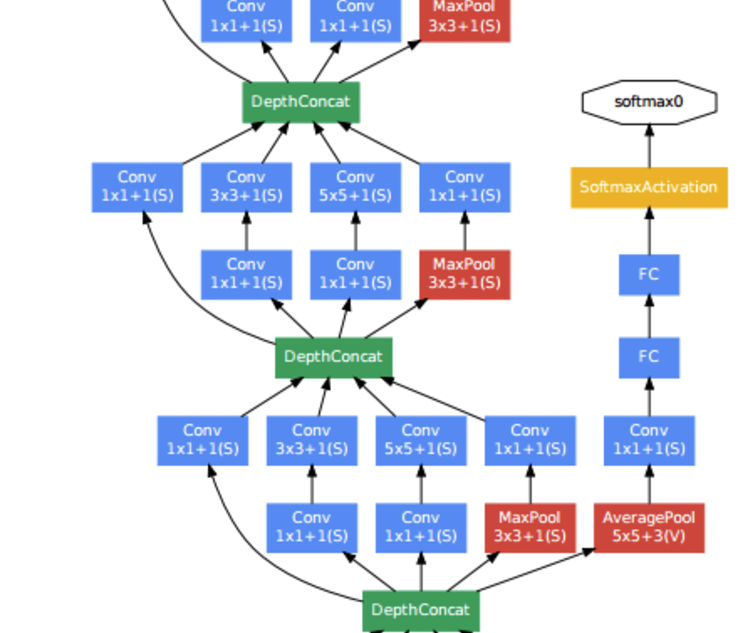
- 그림에서 보면 노란색 의 영역이 눈에 띈다.
- 이는 softmax 영역으로 망 전체에 총 3 개가 있다.
- 실제 마지막 Layer 가 진짜배기 softmax 레이어이고 나머지 2개는 보조 softmax 레이어이다.
- 이는 망이 깊어질 때 발생하는 vanishing 문제를 해결하고자 중간 층에서도 Backprop을 수행하여 weight 갱신을 시도하는 것이다.
- 이렇게하면 당연히 아래 쪽 weight도 좀 더 쉽게 weight가 갱신될 것이다.
- 물론 가장 중요한 softmax 레이어는 마지막 레이어에 연결된 것이므로 보조 레이어는 학습시에 비율을 반영하여 Loss 함수에 반영한다.
- 전체 Loss 값에 0.3 비율로 포함된다고 한다.
- Incecption v2. v3에서는 보조 softmax 가 별로 효용 가치가 없다고 해서 맨 앞단 softmax 는 제거하게 된다.
- 학습(training)시에만 사용하고 추론(inference)시에는 이 노드를 그냥 삭제해버림.
- 즉, 테스트 단계에서는 마지막 softmax 레이어만 실제로 사용함.
- 그래서 pre-trained model 그래프에서는 이 노드가 보이지 않는다.
- 성능 결과는 다음과 같다.
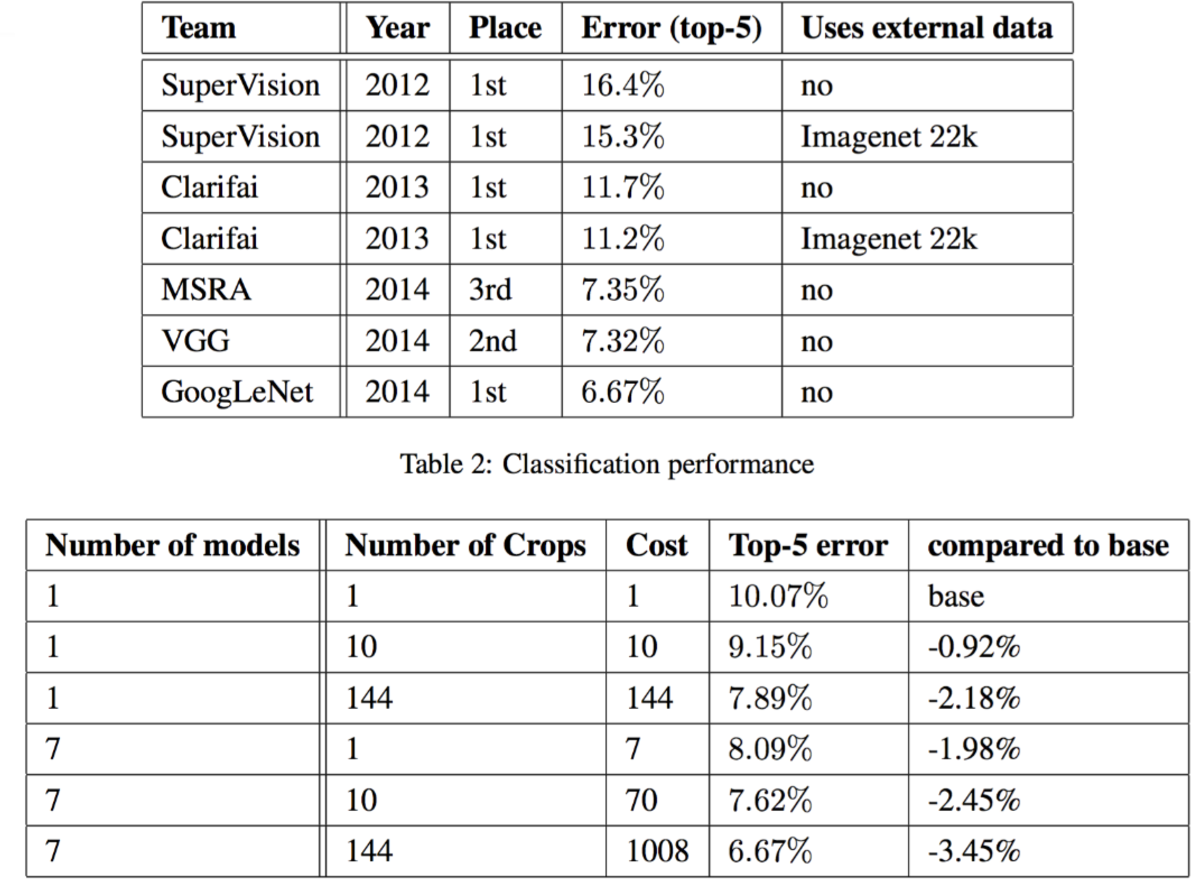
- 다른 Conv-Net 들과의 차이? 예를 들면 VGG 등 (주관적 견해임)
- 그냥 단순히 생각해보면 다른 모델은 conv 영역의 C C (channel) 정보의 경우 localization 이 확실하다고 생각되는데..
- 이건 단순하게 생각하면 동일한 filter 크기를 가지고 W W , H H 의 크기를 줄여나가기 때문에 각 C C 가 담고 있는 정보들은,
- 실제 이미지 데이터에서 차지하는 Localization 영향도가 C C 의 각 차원마다 동일할 것이다.
- 반면 Inception 은 약간 혼성화(mixing, hybriding)된 느낌임.
- 그냥 여러 크기를 가지는 필터를 통해 모아진 정보를 하나의 C C 로 모은 느낌.
- 물론 각 C C 별로 모든 차원의 정보에 대해서는 중심점은 동일하므로 실제 정보는 (C C 축을 기준으로 볼때) 정규분포와 같은 형태로 정보를 모아놓은 느낌.
- 말이 안된다 하겠지만 설명이 잘 안되는 것도 사실.
- 그냥 단순히 생각해보면 다른 모델은 conv 영역의 C C (channel) 정보의 경우 localization 이 확실하다고 생각되는데..
Inception. v2. / v3.
- 관련 논문 : Rethinking the Inception Architecture for Computer Vision
- 구글러의 비애
- 2014년에 1등한건 우린데 왜 VGG만 쓰나? (그럼 좀 쉽게 만들던가!)
- VGG는 연산량이 많는데… 왜?? (그럼 좀 쉽게 만들던가!)
- VGG는 Alexnet보다 파라미터 수가 3배나 많단 말이야! (그럼 좀 쉽게 만들던가!)
- 구글러의 자기 반성
- 내가 생각해봐도 Inception을 응용하기가 쉽지 않다.
- “너님은 능력 부족으로 변형같은건 꿈도 못 꿈”을 말하는듯한 느낌이네
- 반성하고 다른 모델을 고려해본다.
- VGG가 사용한 오로지 3x3 Conv 필터만 사용 이 예상외로 효과가 좋은가보다.
- Conv 연산이 아무리 Sparsity 를 높인다고 하나 여전히 비싼 연산이긴 하다.
- Neural-Net. 디자인 원칙
- (1) Avoid representational bottlenecks, especially early in the network
- (2) Higher dimensional representations are easier to process locally within a network.
- (3) Spatial aggregation can be done over lower dimensinal embeddings without much or any loss in representational power
- (4) Balance the width and depth of the network.
더 작은 단위의 conv 를 사용하자
- 예제로 보는 Conv Factorization.
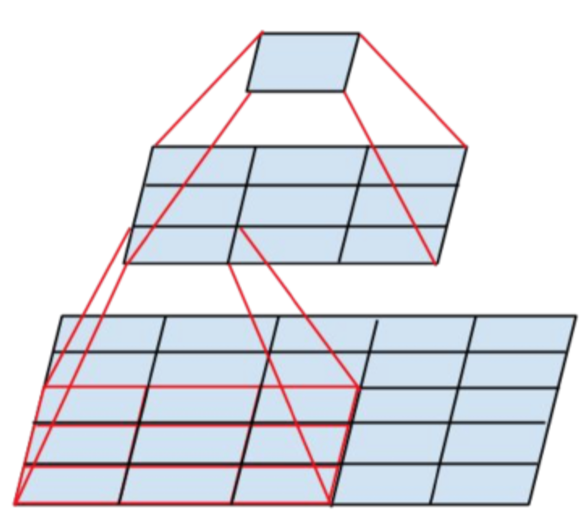
- 5x5 짜리 conv 도 크다. 이걸 3x3 conv 2개로 바꾸어보면,
- 5x5 : 3x3 = 25 : 9 (25/9 = 2.78 times)
- 5x5 conv 연산 한번은 당연히 3x3 conv 연산보다 약 2.78 배 비용이 더 들어간다.
- 만약 크기가 같은 2개의 layer 를 하나의 5x5 로 변환하는 것과 3x3 짜리 2개로 변환하는 것 사이의 비용을 계산해보자.
- 5x5xN : (3x3xN) + (3x3xN) = 25 : 9+9 = 25 : 18 (약 28% 의 reduction 효과)
- 5x5 : 3x3 = 25 : 9 (25/9 = 2.78 times)
- 이제 원래 사용하던 inception 모델에 이를 적용해보자.
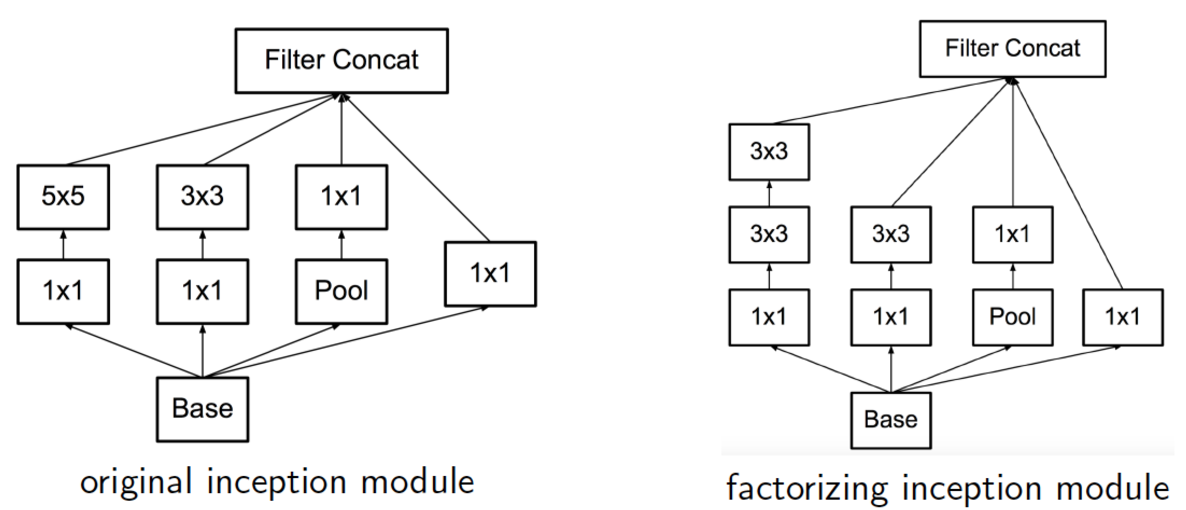
- 이런 모델로 변경했을 때의 2개의 의문?
- 새롭게 바뀐 결과가 Loss 계산에 영향을 주는가?
- Conv 를 두개로 나누게 되면 첫번째 Conv에서 사용하는 Activation 함수는 뭘 사용해야 하는가?
- 실험을 여러번 해봤는데 결과는 꽤 괜찮다.
- 성능에는 문제가 없다.
- Activation은 Relu, Linear 모두 테스트. Relu가 약간 더 좋다.
- 이게 Inception.v2 인가?
- 꼭 그런건 아니고 이 뒤에 소개될 이런 잡다한 기술 몇 개를 묶어 Inception.v2 로 명명한다.
비대칭(Asymmetric) Conv 를 사용한 Factorization
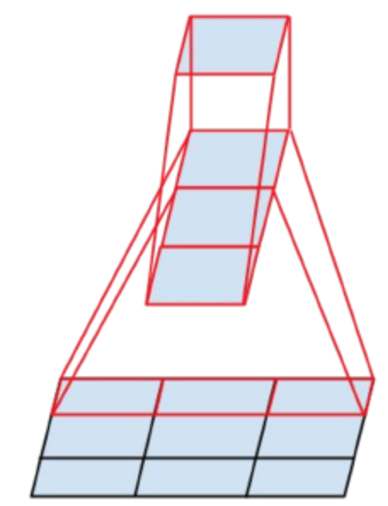
- 마찬가지로 연산량을 줄이면서 Conv 를 할 수 있는 꼼수(?) 기법 중 하나이다.
- 일반적으로 N x N 의 형태로 Conv 를 수행하게 되는데 이를 1 x N 과 N x 1 로 Factorization 하는 기법이다.
- 계산을 해보면 연산량이 33% 줄어든다.
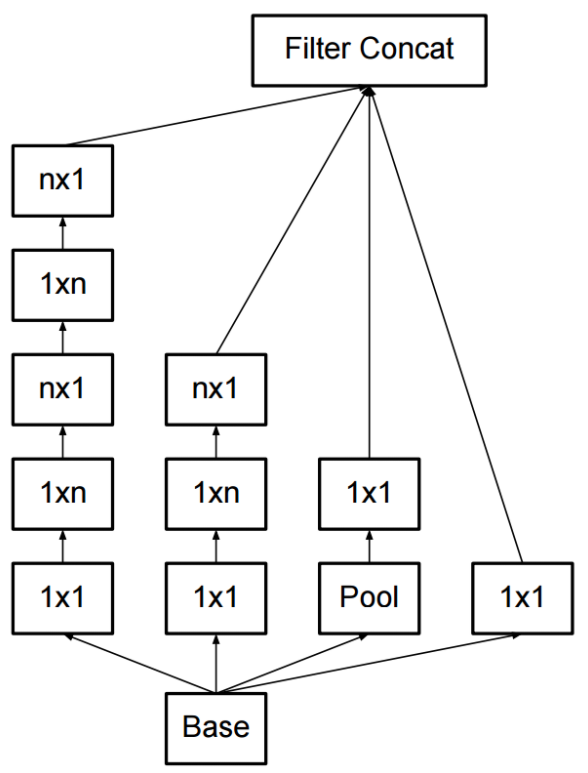
보조 분류기 (Auxiliary Classifiers)
- 앞서 Inception.v1 에서는 맨 마지막 softmax 말고도 추가로 2개의 보조 softmax 를 사용했다고 이야기했다.
- Backprop시 weight 갱신을 더 잘하라는 의미에서.
- 이 중에 맨 하단 분류기는 삭제한다. 실험을 통해 성능에 영향을 주지 못하는 것으로 확인되었다.
효율적인 그리드(Grid) 크기 줄이기
- CNN 은 Feature Map의 Grid 크기를 줄여가는 과정을 Max-Pooling 을 이용해서 진행한다.
- 그리고 언제나 Pooling 은 Conv와 함께한다.
- 그럼 어떤걸 먼저해야 효율적인 Grid 줄이기를 할 수 있을까?
- Pooling 을 먼저할까? Conv 를 먼저할까? 최종적으로 얻어지는 크기는 동일함.
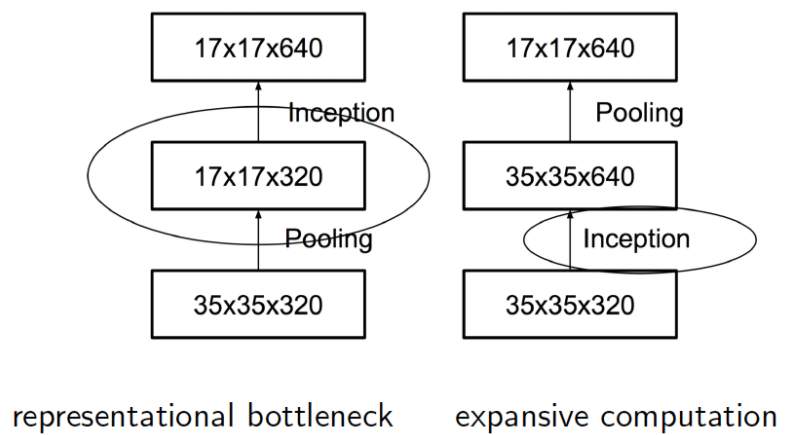
- 일단 왼쪽은 Pooling을 먼저 하는것. 오른쪽은 Conv 를 먼저하는것.
- 결론부터 말하면 둘 다 별로.
- Pooling을 먼저하면?
- 이 때는 Representational Bottleneck 이 발생한다.
- 이 말의 정확한 의미를 이해하기는 어렵지만 (실제로는 심리학 용어인듯) 대충 Pooling으로 인한 정보 손실로 생각하면 될 듯 하다.
- 예제로 드는 연산은 (d,d,k) (d,d,k) 를 (d/2,d/2,2k) (d/2,d/2,2k) 로 변환하는 Conv 로 확인. (따라서 여기서는 d=35 d=35 , k=320 k=320 )
- 어쨌거나 이렇게 하면 실제 연산 수는,
- pooling + stride.1 conv with 2k filter => 2(d/2) 2 k 2 2(d/2)2k2 연산 수
- strid.1 conv with 2k fileter + pooling => 2d 2 k 2 2d2k2 연산 수
- 즉, 왼쪽은 연산량이 좀 더 작지만 Representational Bottleneck 이 발생.
- 오른쪽은 정보 손실이 더 적지만 연산량이 2배.
- 어쨌거나 이렇게 하면 실제 연산 수는,
- 이제 결론을 이야기하자.
- 결국 둘 중 하나를 선택하지 못한다면 섞어버리는게 딱 좋은데, 연산량을 낮추면서 Representation Bottleneck 을 없애는 구조를 고민한다.
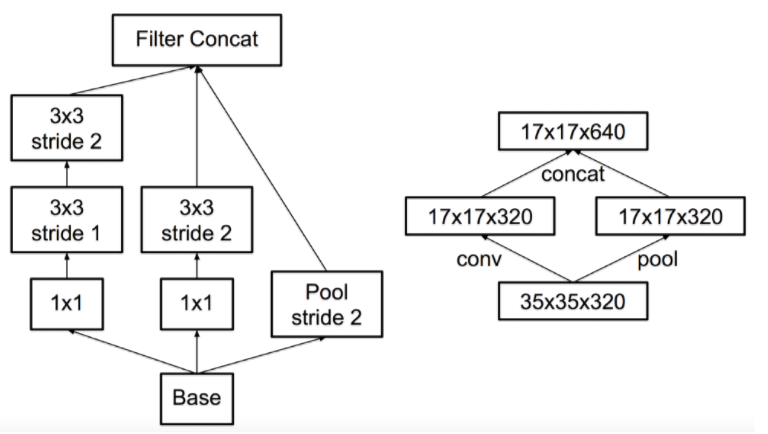
- 대단한 것은 아니고 두개를 병렬로 수행한 뒤 합치는 것. (먼저 오른쪽 그림을 보자)
- 이러면 연산량은 좀 줄이면서 Conv 레이어를 통해 Representational Bottleneck을 줄인다.
- 이걸 대충 변경한 모델이 왼쪽이라고 생각해도 된다.
Inception.v2
- 이제 Inception.v2 가 나온다.
- 지금까지 설명했던 것들을 대충 모으면 Inception.v2 모델이 된다.
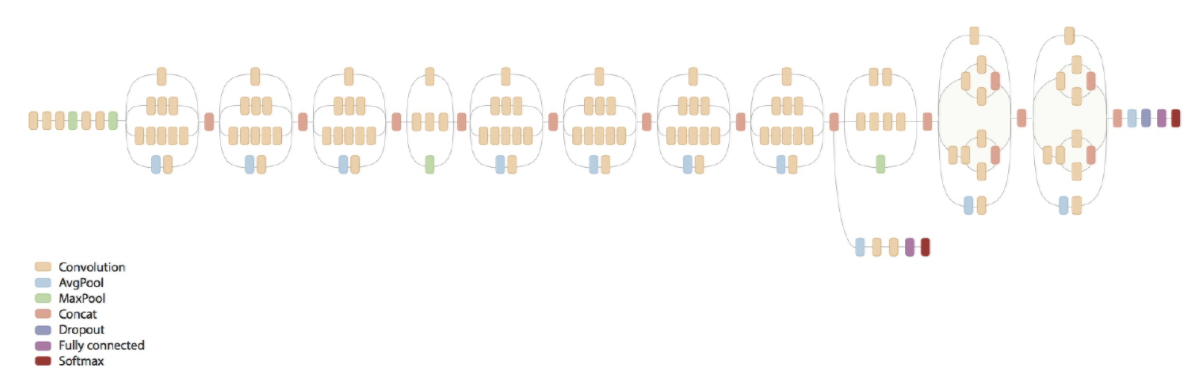
- 이 그림은 익숙할 것이다. 이게 Inception.v2 다.
- 어떤 사람은 이 그림을 Inception.v3 로 알고 있는 사람이 있는데 이유가 있다. 뒤에 나온다.
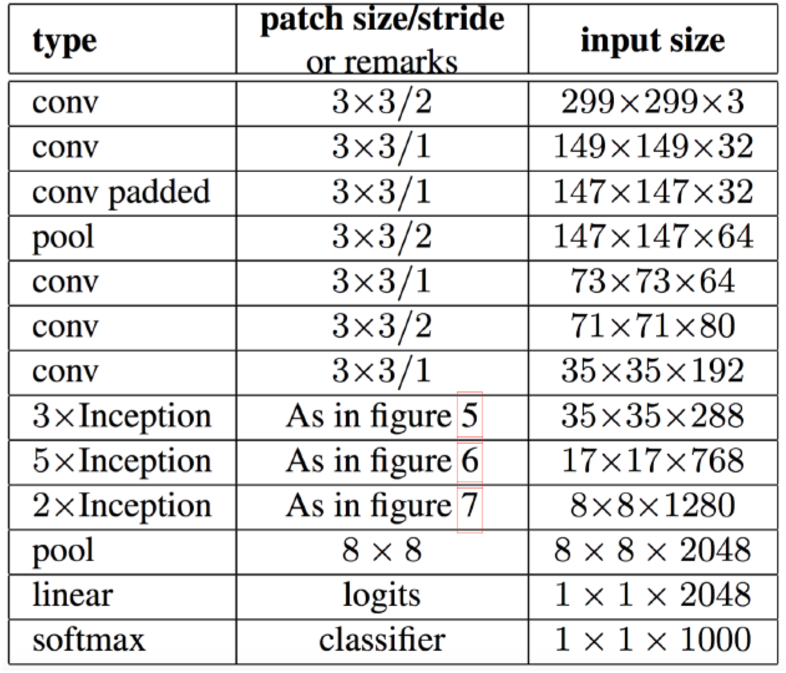
- 잘 보면 레이어 앞단은 기존 conv 레이어와 다를 바 없다. (stem 레이어)
- 중간부터 앞서 설명한 기본 inception 레이어 들이 등장한다.
- 중간 아래에는 figure 5, 6, 7 라고 표기되어 이것은 앞서 설명한 여러 기법들을 차례차레 적용한 것이다.
- 친절하게 다시 그림으로 정리해본다.
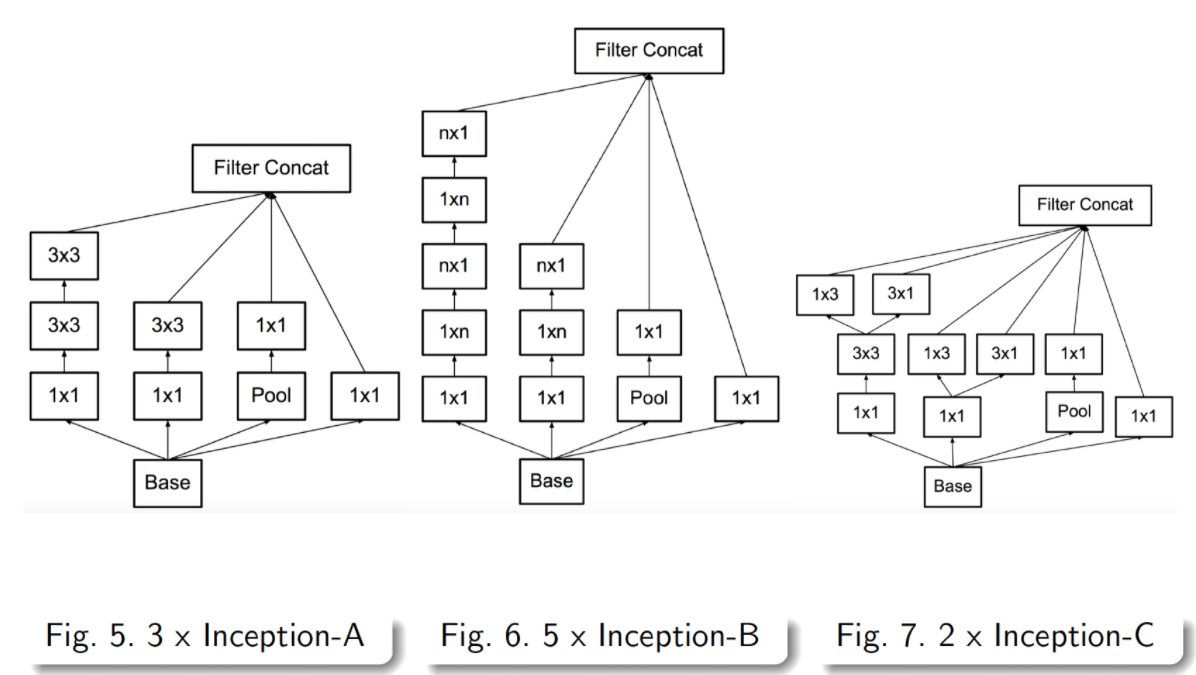
Inception.v3
- Inception.v3는 Inception.v2 를 만들고 나서 이를 이용해 이것 저것 수정해보다가 결과가 더 좋은 것들을 묶어 판올림한 것이다.
- 따라서 모델 구조는 바뀌지 않는다. 그래서 Inception.v2 그 구조도를 그대로 Inception.v3 라 생각해도 된다.
- 사실 Inception.v3 모델을 Inception.v2++ 정도로 봐도 무방하겠다.
- 간단하게 정확도로 이를 확인해보자.
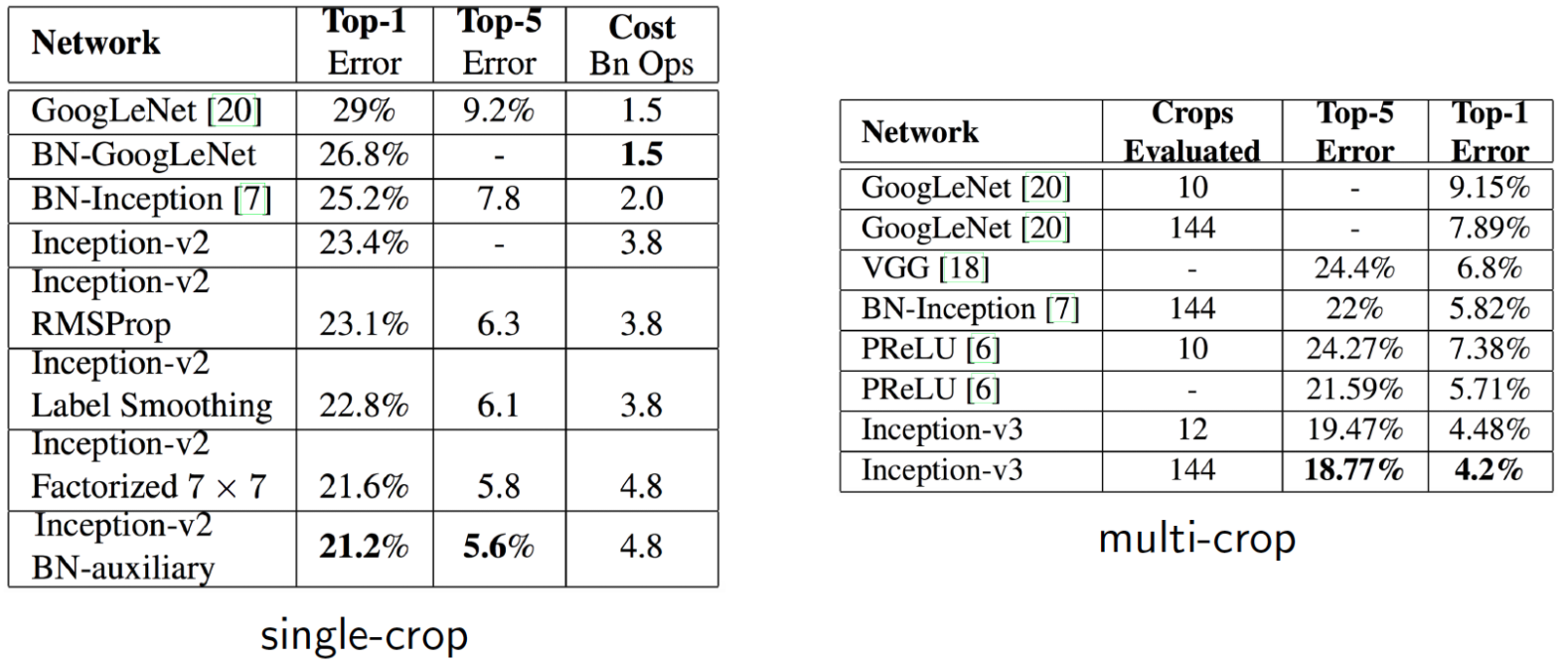
- 왼쪽만 보면 되는데 Inception.v2 기본 버전의 top-1 error 값이 23.4 % 인 걸 알 수있다.
- 여기서 이제 각종 기능을 붙여본다.
- RMSProp : Optimizer를 바꾼거다.
- Label Smoothing
- 논문에 자세히 나와있긴 한데 간단히 설명하자면 Target 값을 one-hot encoding을 사용하는 것이 아니라,
- 값이 0 인 레이블에 대해서도 아주 작은 값 e e 를 배분하고 정답은 대충 1−(n−1)∗e 1−(n−1)∗e 로 값을 반영하는 것이다.
- Factorized 7-7
- 이게 좀 아리까리한게 맨 앞단 conv 7x7 레이어를 (3x3)-(3x3) 2 레이어로 Factorization 한 것이라고 한다. (앞에서 설명한 것이다.)
- 그런데 v2 레이어 표를 보면 이미 적용되어 있는 것 같기도 해서 혼동이…
- 어쨋거나 이를 적용했다고 한다. 일단 넘어가자.
- BN-auxiliary
- 마지막 Fully Conntected 레이어에 Batch Normalization(BN)을 적용한다.
- 이를 모두 적용한게 Inception.v3 되겠다.
- 최종 결과값만 보자.
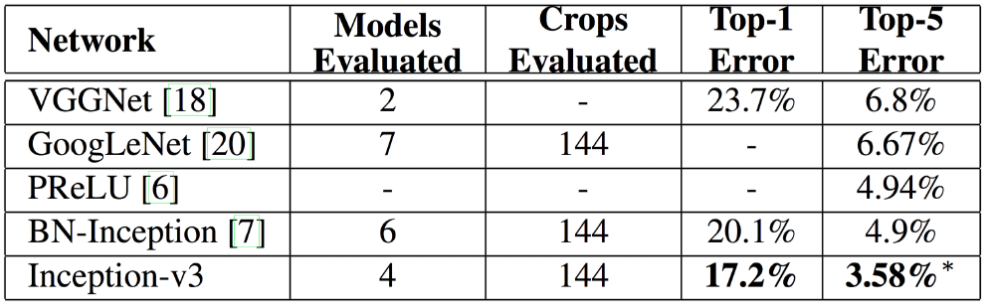
- 뭐 성능은 좋다 한다.
참고사항
- 우리가 pre-trained 모델로 사용하는 Inception은 Inception.v3 버전이다.
- 하지만 논문에서 설명하는 Inception.v3 버전과는 완벽하게 일치하지 않는다.
- 내부적으로도 버저닝(versioning)이 잘 안되나보다. 날짜로 확인을 해야 한다.
Inception.v4 & Inception-resnet
- 관련 논문 : Inception-v4, Inception-RestNet and the Impact of Residual Connections on Learning
- 2015년 혜성과 같이 등장한 ResNet 을 자연스럽게 자신들의 Inception에 붙여보려는 시도.
- 그런데 이건 존심의 문제인지 Inception.v4 에 반영된 것이 아니라 Inception-resnet 이라는 별도의 모델로 작성.
- Inception.v4 는 기존의 Inception.v3 모델에 몇 가지 기능을 추가시켜 업그레이드한 모델.
- 따라서 이 논문은 Inception.v4 와 Inception-resnet 둘을 다루고 있다.
- 특히나 resnet 을 도입한 모델을 Inception-resnet 이라 명명한다.
- 마찬가지로 이 버전도 Inception-resnet.v1, Inception-resnet.v2 와 같이 별도의 버저닝을 가져간다.
- 실제로는 ad-hoc한 모델로 이 모델의 한계점을 이야기하고 있음.
- 관련 작업들.
- TensorFlow를 언급
- 예전 Inception 버전은 구현 모델의 제약이 많았음.
- TensorFlow로 전환 후 유연한 모델을 얻게 됨.
- 뒤에 나올 그림들을 살펴보면 Inception-v4 가 어떤 모델인지 알수 있게 될 것이다.
- TensorFlow를 언급
- Residual connections
- 사실 깊은 망을 학습할 경우 (이미지 인식 분야에서) 이게 꼭 필요한 것인지는 우리(구글러)끼리 논쟁 중.
- 근데 확실히 학습 속도가 빨라진다. 그건 장점.
- Residual connection 이 뭔지 모르는 사람을 위한 그림. 아래를 참고하자.
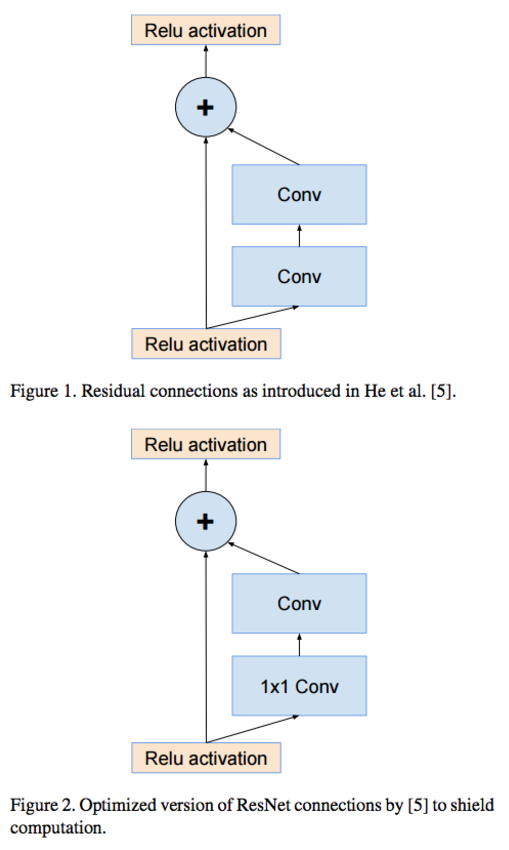
- 일단 첫번째 그림이 가장 간단한 형태의 residual-connection을 의미.
- 두번째는 1x1 conv 를 추가하여 연산량을 줄인 residual-connection을 나타낸다.
- 어쨌거나 Residual 의 개념은 이전 몇 단계 전 레이어의 결과를 현재 레이어의 결과와 합쳐 내보내는 것을 의미한다.
Inception-v4. , inception-resnet-v2
- 일단 Inception.v4 의 전체 망을 조망해본다. 감상해보자.
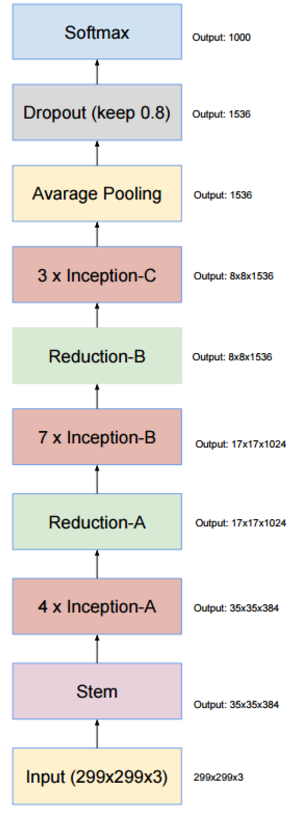
- inception-v3 와 마찬가지로 거의 유사한 형태의 net 을 구성하고 있지만 세부적인 inception 레이어의 모양이 달라진다.
- 이건 지금부터 확인해 볼 것이다.
Versioning
- Inception에 resnet 이 추가되면서 버저닝이 좀 정신사나워졌다.
- 일단 앞서 이야기한대로 Inception.v3를 확장한 Inception.v4 는 별도로 존재.
- 여기에 Inception.v3와 Inception.v4에 각각 residual 을 적용한 버전이 Inception-resnet.v1, Inception-resnet.v2 이다.
- 즉, Inception.v3 에 대응되는 resnet은 Inception-resnet.v1
- 즉, Inception.v4 에 대응되는 resnet은 Inception-resnet.v2
Stem Layer
- Inception.v3 에서 앞단의 Conv 레이어를 stem 영역이라고 부른다고 이미 이야기했다.
- Inception.v4 에서는 이 부분을 약간 손봤다.
- 그리고 미리 이야기하지만 Inception-resnet.v2 버전에서도 Stem 영역은 동일하게 이 구조를 사용한다.
- 먼저 stem 영역의 그림을 보자.
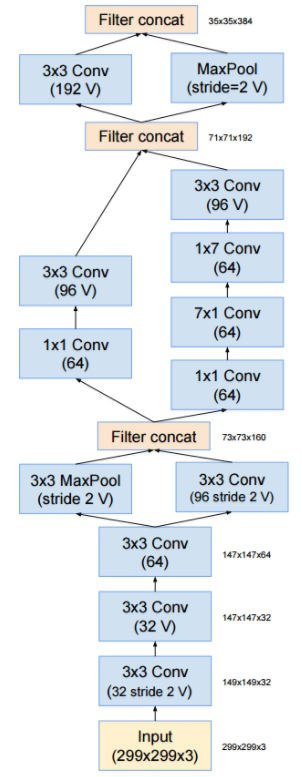
- 이런 구조가 나오게 된 배경 지식은 이미 Inception.v3 에서 다루었고, 다만 Inception.v4 에서는 앞단의 영역에도 이런 모델이 추가로 차용되어 있다고 생각하면 된다.
- 아마도 이것저것 테스트해보다가 결과가 더 좋게 나오기 때문에 이를 채용한 것 같다.
4 x Inception-A
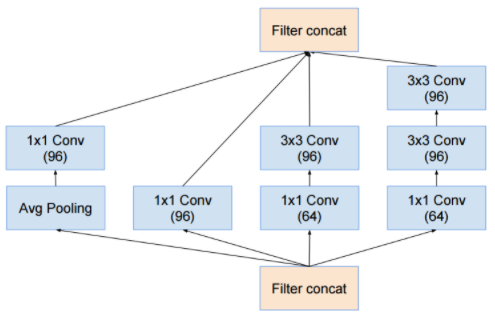
7 x inception-B
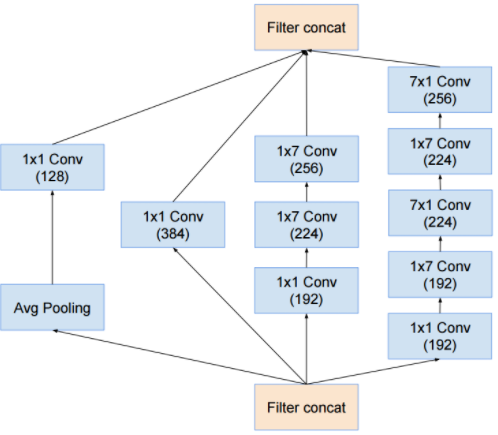
3 x inception-C
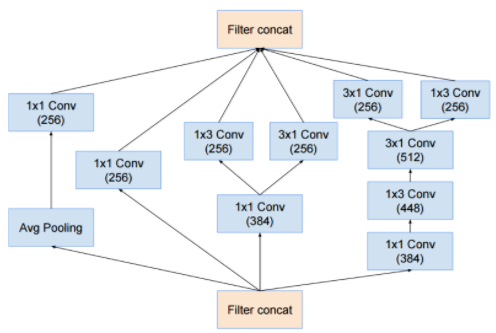
- 위에서 설명된 Inception 모듈은 모두 입출력 크기 변화가 없다. (inception module 의 input, output 크기를 의미한다.)
- 실제 크기 변화가 발생하는 부분은 Reduction 이라는 이름을 사용한다.
Reduction-A
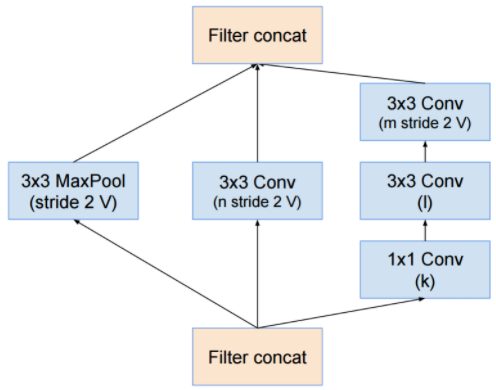
Reduction-B
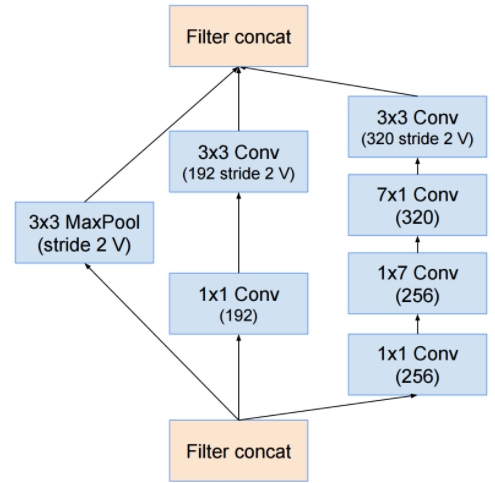
- 사실 Inception.v4 모델에서는 새로운 컨셉이 등장하거나 한 것은 없다.
- 기존의 Inception.v3 모델을 이것저것 실험해보면서 좋은 결과를 얻는 case를 조합한 느낌이다.
Resnet
- 일단 논문에서는 Inception-resnet.v1과 Inception-resnet.v2 를 구분하여 그림으로 설명을 하고 있다.
- 특별히 설명할 것은 없고 몇 가지 그림만 보고 넘어가도록 하자.
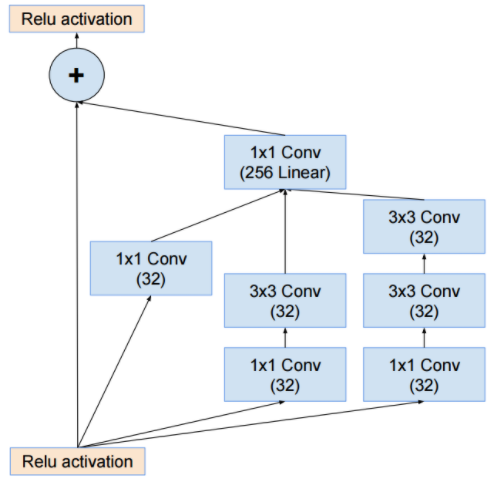
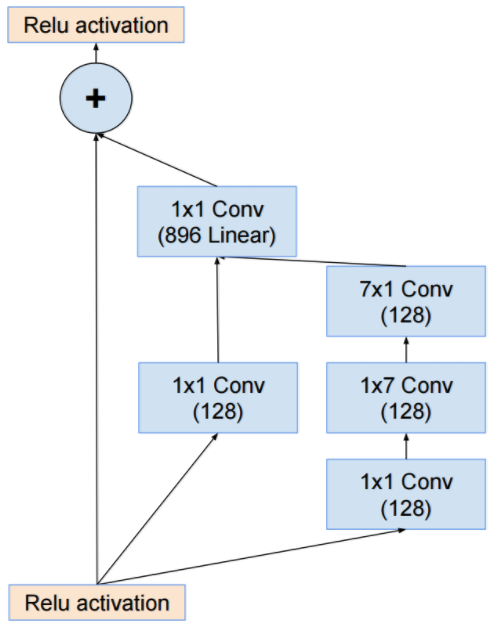
- 특별한 내용은 없고 그냥 residual 만 추가한 것이다.
결과
- resnet 도입으로 얻을 수 있는 장점은 학습 수렴 속도
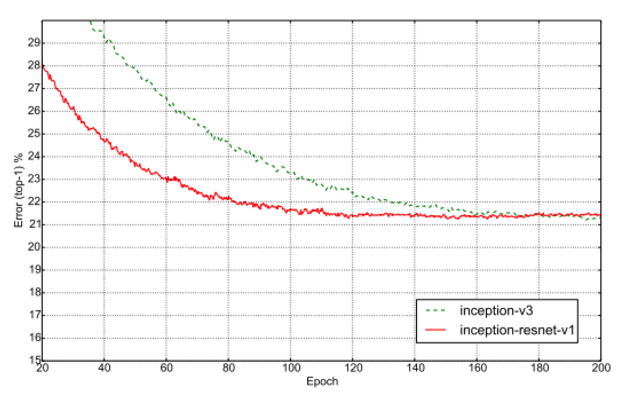
- 위의 그림은 Inception.v3 와 Inception-resnet.v1 의 에러 값 수렴 속도를 나타내고 있다.
- resnet 이 훨씬 빠르게 수렴된다는 것을 알 수 있다.
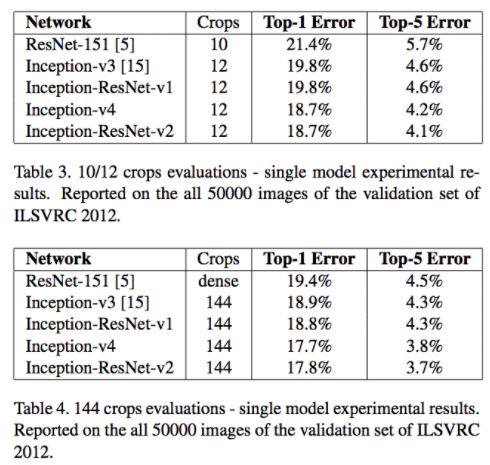
- 마지막으로 성능 지표는 다음과 같다.
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 1519 | JAMA | WHRIA | 2017.02.11 | 722 |
| 1518 | windows faster rcnn | WHRIA | 2017.02.10 | 4718 |
| » | inception | WHRIA | 2017.01.23 | 7254 |
| 1516 | fast rcnn | WHRIA | 2017.01.08 | 146 |
| 1515 | fast rcnn cudnn 5.0 | WHRIA | 2017.01.08 | 180 |
| 1514 | jquery java | WHRIA | 2016.12.13 | 1850 |
| 1513 | % 빼고 center crop | WHRIA | 2016.10.22 | 361 |
| 1512 | 이미지를 정사각형으로 만드는 batch | WHRIA | 2016.10.22 | 1222 |
| 1511 | 이미지 size 줄이는 batch | WHRIA | 2016.10.19 | 169 |
| 1510 | caffe | WHRIA | 2016.10.19 | 145 |
| 1509 | sqlite to mysql | WHRIA | 2016.10.18 | 182 |
| 1508 | KMA 연수교육 주소 | WHRIA | 2016.10.05 | 184 |
| 1507 | . | WHRIA | 2016.10.01 | 120 |
| 1506 | 만기까지 끌어 올림. | WHRIA | 2016.09.30 | 116 |
| 1505 | youtube | WHRIA | 2016.09.30 | 81 |